
『Designing for the Social Web』을 마무리 하고 있습니다.『소셜 웹 기획』이란 제목을 달았죠. (며칠 전 강규영 님께서 서평을 올리셨던 바로 그 책입니다.)
번역이 끝난 지는 오래고, 초교, 재교, 삼교까지 끝났지만, 아직 마무리 선언을 못하고 있습니다. 색인 때문이죠. 원서로 200쪽, 번역서 240여 쪽에 불과한 책에 색인이 자그마치 1,000여 개가 붙어있으니까요.
색인 1,000개가 별 일 아닌 거 같이 보이기도 합니다. 사실 키워드를 뽑아 1단으로 배열하는 수준이라면 아주 큰 일은 아닐 수 있죠. 하지만 색인을 2단 혹은 3단으로까지 배열한다고 생각하면 그리 쉽게 생각할 수 없는 작업이 됩니다.
1단으로 색인을 정리한다면, 키워드를 뽑거나 원서의 인덱스를 정리해, 편집 프로그램(주로 Quark 프로그램)에서 색인 항목으로 설정하고, 설정된 단어를 모아(자동으로) 가나다/ABC 순으로 정리하면 끝입니다.
그런데 2, 3단의 인덱스를 뽑는다면 일이 그리 만만치 않습니다. 한번 과정을 볼까요?

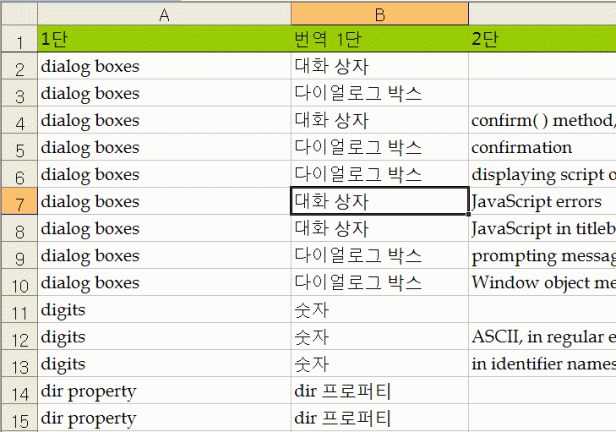
위 원서의 색인을 긁어 엑셀로 올립니다.
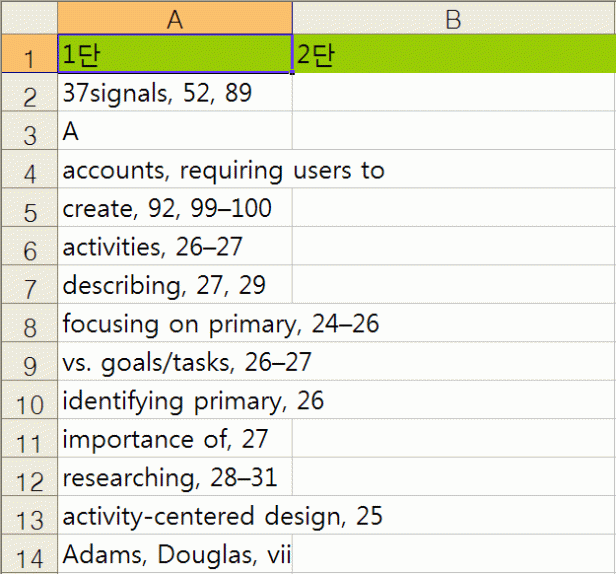
에고 New Riders의 책은 PDF에서 긁으면 들여쓰기가 먹지 않네요.
이걸 일일이 원서 모양대로 2단으로 정렬합니다.
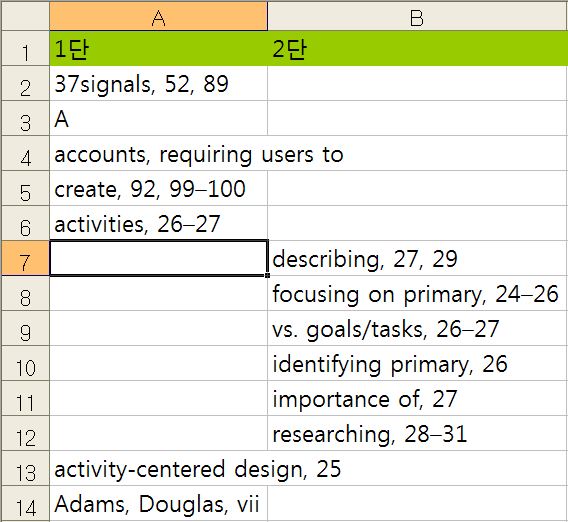
이어지는 작업을 위해 다시 아래와 같이 정리해야 합니다.
쪽수도 일일이 다시 떼어 붙여야 하죠.
또, 같은 단어가 여러 페이지에 걸쳐 색인된 단어는 모두 별도의 항목으로 만들어야 합니다.
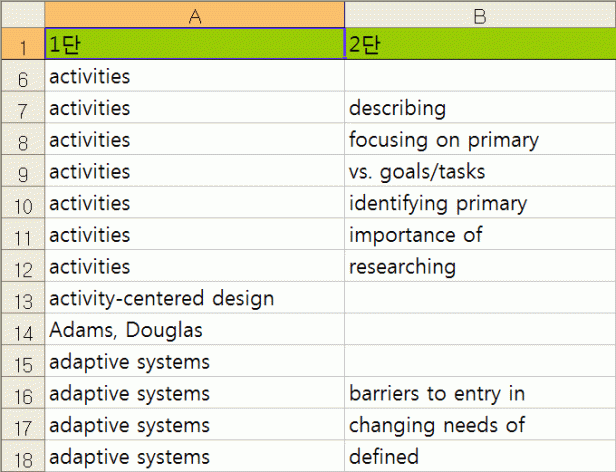
여기까지는 색인을 위한 기초 작업이고 이제 본격적으로 색인을 뽑기 시작한다고 할 수 있습니다.
위 영문으로 정렬한 단어들을 대략적으로나마 번역합니다. 여기서 대략이라고 한 건, 본문에 어떻게 되어 있는지 아직 확인하지 않았기 때문입니다. 번역을 하시면서 대부분의 단어가 어떻게 번역되었는지 기억하긴 하지만, 사람의 기억력이란 게 불완전할 뿐 아니라, 단어 대 단어로 대치되는 것만 있는 게 아니라, 문장 속으로 풀어헤쳐진 단어들도 있으니까요.
이제 이 파일을 쪽수 순으로 정렬합니다.
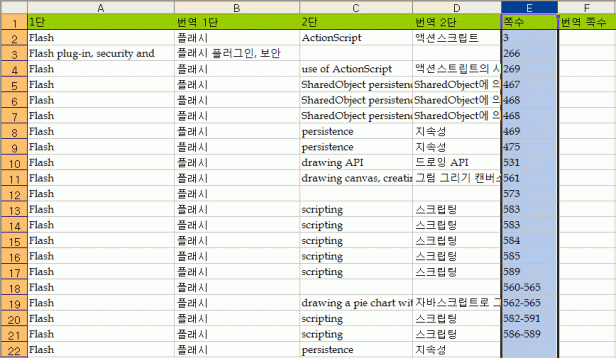
이런 과정을 밟아야 1, 2, 3단이 흐트러지지 않기 때문에 위에서 엑셀 각 항목에 공백이 생기지 않게 정리한 겁니다. 일일이 수작업으로…. ㅠㅜ
이제 번역문과 비교할 차례입니다. 비록 원서와 번역서의 쪽수가 달라졌으나, 색인 항목은 쪽수 순으로 정돈되어 있으니 차례로 찾으면 되겠죠.
여기서도 조금 더 성의 있게 색인을 뽑는다면, 영문 단어로 많이들 알고 계신 단어들은 영문으로도 별도로 뽑고, 사람 이름은 음가로도 뽑고, 영문으로도 뽑습니다. 영문 색인에는 사람 이름이 성+이름(예, Fowler, Martin)으로 되어 있으나, 흔히 이름+성(예 : Martin Fowler)으로 기억하기 때문에 영문으로 이름+성 항목의 색인도 만듭니다.(혹시 문헌학을 공부하신 분들이라면 이견이 있을 수 있으니, 잘못되었다면 알려주시길)
물론 원서의 색인이라고 완벽할 수는 없기 때문에, 꼭 들어가야 할 키워드가 빠졌다면 추가해야겠죠.
이렇게 쪽수를 모두 찾아 넣고 제대로 정렬하면 될까요? 그게…… 참 어렵습니다.
색인에 좀 더 완벽을 기하려면 원래 영문 순으로 다시 정렬해 보는 게 좋습니다.
이 작업을 하는 이유는 색인이 수백 개 수준이라면 각 단어가 어떻게 번역되었는지 거의 기억하며 색인 작업을 하겠지만, 1,000개를 넘어 수천 개 수준이라면 기억력에 한계가 생기기 때문에, 영문으로 다시 정렬해 보면 또 다른 점검/수정 사항들이 눈에 띄거든요.
휴~ 이제 마무리 수순입니다.
위에서 밟아왔던 과정을 거꾸로 해나가면서 정리하면 됩니다.
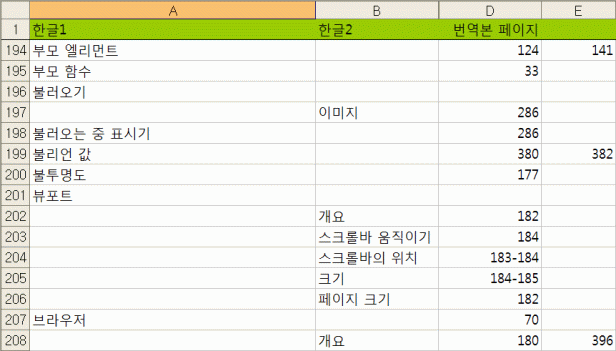
한글로 번역해 쪽수로 정렬된 색인을 가나다/ABC 순으로 다시 정렬하고
로마자로 페이지가 되어 있거나, 00쪽~0x쪽 식으로 되어있는 부분들까지 제대로 순서가 맞는지 하나하나 꼼꼼히 점검하고, 따옴표 등 특수문자 때문에 순서가 엉킨 단어들을 바로잡고, 정렬을 위해 불필요하게 채워 넣었던 1단(혹은 2단)의 항목들을 지우고, 같은 항목 색인임에도 여러 열을 차지하는 단어들(쪽수)을 한 칸에 모읍니다.
이제 완성되었습니다. 위에서 완성한 엑셀 파일을 텍스트로 전환해 디자이너에게 주면 Quark 프로그램에 올려 다듬고 나면 마무리입니다.
어떠세요. 쉽지 않죠?
참고로, jrogue 님의 예전 블로그에 들어가면 색인 작업을 ‘인형 눈 붙이기’에 비교해 재밌게 써놓으신 글이 있습니다. 방식은 조금씩 차이가 있겠지만 고통스러운 작업이라는 건 그리 다르지 않습니다.
이렇게까지 어렵게 작업하는 건, 문맥까지 파악하고 필요한 내용을 찾는 데 도움이 되려면 키워드만 뽑는 1단 인덱스로는 미흡하기 때문입니다. 또, 위에서 설명하면서 얘기드렸지만 용어 사용이 달라진 부분을 확인할 수 있기 때문입니다. 때론 원서의 오류까지 보이기도 하구요.
아~~ 이렇게 작업할 땐, 번역문 쪽수가 변동되지 않는다는 걸 전제로 하는데, 한참 색인 작업을 마무리 하는데 이러저런 수정으로 쪽수에 변동이 생기면….. ㅎㅎㅎ
그래서 저흰 역자를 섭외하면서, 처음 번역하시거나, 이런 인덱스 작업을 해보지 않으신 분들에게 꼭 말씀드립니다.
번역이 끝나셨다고 할 일이 마무리 되시는 건 아니라고.
나중에 색인을 뽑는 노가다가 기다리고 있으니 꼭 시간을 비워 놓으시라구요. ^^
ps 1 저희 책도 예전에 만든 책들은 이런 과정을 거쳐 색인을 만들지 않았습니다. 어떻게 해야 색인을 제대로 뽑을까 고민하며, 몇 번의 시행착오를 거친 끝에 위와 같은 프로세스가 정리된 거죠. 아마 ‘노가다’를 줄일 더 나은 방법을 아시는 분들이 계실 텐데, 알려주시면 감사하겠습니다.
ps 2 거창하게 정리하긴 했지만, 이렇게까진 색인을 뽑지 못하는 경우도 생길 겁니다. 제한된 시간 때문에 ‘시간 싸움’을 해야 할 경우겠죠. 그런 일은 만들지 않아야겠지만 도망갈 구멍은 마련해 봅니다. ^^a

이틀전에 포스팅해서 전문서적에 인덱스 없으면 참 힘들다고 투정부렸는데
다른 출판사의 편집자분이 인덱스 만드는 거 진짜 어렵고 힘들다고 토로하시더니
인사이트 블로그에서 그 어려움을 정확히 알려주시네요 ㅎㅎㅎ
수작업으로 저렇게 만들어지고 있다니
정말 ‘노가다’라는 말이 딱이네요
고생들이 많으시구나 ^^
그래도 색인 없는 책은 앙꼬없는 찐빵이랄까…
독자들을 위해서 힘내주세요!!!
좋아요좋아요
레몬에이드님이 자동으로 색인을 만드는 프로그램을 만들어 주심 되는거임
(나는 누구일까요?)
좋아요좋아요
예전에 다른 책을 만들면서 자동화를 시도했던 적이 있습니다. 결과는 음… 이러저런 예외 때문에 손으로 하는 만큼의 시간이 걸려 포기했죠.
혹시라도 누군가 만들어 주신다면 감사히 쓰겠습니다.
또, ‘수작업’을 벗어나지 못하는 출판계에도 큰 도움이 될 겁니다. ^^
좋아요좋아요
오, 이 책이 번역되서 나오는군요. 원서 살뻔했는데 잘됐다…ㅋㅋ
좋아요좋아요
이제 금방 나옵니다. ^^
근데… fribirdz 님은 웹애스콘에서 여러 번 눈앞을 스쳐 지나가셨는데, 못알아보시는 거 같아 섭섭했다는…. ㅎㅎㅎ
좋아요좋아요
어, 아니예요. ㅋㅋ 못알아본건 아니고, 저도 멀리서 한사장님 지나가시는거 보고 ‘있다가 인사드려야지.. ‘했었는데, 그 이후로 못뵈서 =.=
당일날 이것저것 하냐고 좀 바빠서 정신이 없었네요. 흐..
4일전에 jquery in action 샀으니 봐주세요. ㅋㅋ
좋아요좋아요